How does CPython print stack traces?
Thomas Pelletier | Jul 18th, 2023
Python is the most popular programming language in the world. It’s expressive, flexible, and often fast enough. Sometimes it isn’t, and knowing why is the key to making the right next move. CPU and memory profiling is a great tool to understand where the program spends its resources and helps track down the most beneficial performance improvements.
A couple of months ago, we open-sourced wzprof – a pprof-based CPU and memory profiler for all programs, using WebAssembly. As an instrumenting profiler, it captures the application’s call stack at specific points. It symbolizes each frame to display to the user where the call occurred (which function, file, line number).
wzprof captures the Wasm stack and symbolizes it with the DWARF debugging information if they are available. It’s a good default since it works nicely out of the box if the Wasm module was compiled from C, Rust, or Zig, for example. However, it’s not a great experience if the compiler doesn’t provide DWARF information or manages the program’s call stack separately. This is the case for programs compiled by Golang. So last month, we built some smarts to walk the actual call stack of Go programs and symbolize without needing DWARF.
After doing this work, I wanted to learn how to do the same for Python. The goal is to walk a call stack and perform symbolization to provide the user with meaningful profiling information to understand their program’s performance. But Go and Python significantly differ in this context: Go is a compiled language, and Python has an interpreter. The WebAssembly Virtual Machine executes the user’s Go program but runs the Python interpreter (CPython), which runs the user’s Python program.
CPython is the standard Python interpreter; as hinted by the name, it is a C program. When compiled to WebAssembly, it uses the Wasm call stack, and when assembled correctly, the Wasm module contains DWARF information. Running it with wzprof provides CPU and memory profiles but of the interpreter! It’s great if you’re working on CPython itself, but it doesn’t say much if you are writing Python code and are interested in how it’s doing performance-wise. Measuring and displaying the Python call stacks would be more beneficial than CPython’s.
So the question became: how does CPython print stack traces?
The answer had to live in its code base. Put on your wetsuit and scuba gear; we’re going to explore the depths of this software sea…
Dive into CPython internals
Let’s look at the CPython 3.11 code. It’s essential because this version has changed the mechanisms we will look at, so our learnings will be more relevant to present and future programs.
Having written a bit of Python in my career, I remembered the traceback module. It provides means to “extract, format, and print stack traces of Python programs.” It has a function aptly named print_stack. Its code is in Lib/traceback.py:
def print_stack(f=None, limit=None, file=None):
"""Print a stack trace from its invocation point.
The optional 'f' argument can be used to specify an alternate
stack frame at which to start. The optional 'limit' and 'file'
arguments have the same meaning as for print_exception().
"""
if f is None:
f = sys._getframe().f_back
print_list(extract_stack(f, limit=limit), file=file)
source: Lib/traceback.py
Stack walking
The first thing we need to do is walk the stack to capture a snapshot of where the program is at. print_stack starts by finding what seems like a reference to the stack frame of the caller:
f = sys._getframe().f_back
The sys module is a core C module, so its source is at Python/sysmodule.c:
static PyObject *sys__getframe_impl(PyObject *module, int depth)
{
PyThreadState *tstate = _PyThreadState_GET();
_PyInterpreterFrame *frame = tstate->cframe->current_frame;
if (frame != NULL) {
while (depth > 0) {
frame = frame->previous;
if (frame == NULL) {
break;
}
if (_PyFrame_IsIncomplete(frame)) {
continue;
}
--depth;
}
}
if (frame == NULL) {
_PyErr_SetString(tstate, PyExc_ValueError,
"call stack is not deep enough");
return NULL;
}
PyObject *pyFrame = Py_XNewRef((PyObject *)_PyFrame_GetFrameObject(frame));
if (pyFrame && _PySys_Audit(tstate, "sys._getframe", "(O)", pyFrame) < 0) {
Py_DECREF(pyFrame);
return NULL;
}
return pyFrame;
}
source: Python/sysmodule.c
Like Go, the first step is finding the current thread state, presumably with _PyThreadState_GET. This function is defined in Include/internal/pycore_pystate.h:
static inline PyThreadState* _PyThreadState_GET(void)
{
return _PyRuntimeState_GetThreadState(&_PyRuntime);
}
static inline PyThreadState* _PyRuntimeState_GetThreadState(_PyRuntimeState *runtime)
{
return (PyThreadState*)_Py_atomic_load_relaxed(&runtime->gilstate.tstate_current);
}
source: Include/internal/pycore_pystate.h
First, we need to find the _PyRuntime value. This is a static global of type _PyRuntimeState defined in pycore_runtime.h.
Googling the name of this symbol, I found py-spy: https://github.com/benfred/py-spy. It seems to do basically what we want to do with wzprof but with native applications. Their README says:
Getting the memory address of the Python Interpreter can be a little tricky due to Address Space Layout Randomization. If the target python interpreter ships with symbols it is pretty easy to figure out the memory address of the interpreter by dereferencing the
interp_heador_PyRuntimevariables depending on the Python version. However, many Python versions are shipped with either stripped binaries or shipped without the corresponding PDB symbol files on Windows. In these cases we scan through the BSS section for addresses that look like they may point to a valid PyInterpreterState and check if the layout of that address is what we expect.
We can restrict ourselves to CPython builds that contain debug symbols. In this case, we will use a Wasm+WASI build of CPython that we distribute with timecraft. Let’s dump the DWARF sections of our python.wasm module, we can see that it contains:
$ dwarfdump python.wasm
//...
< 1><0x0000003e> DW_TAG_variable
DW_AT_name _PyRuntime
DW_AT_type 0x0000004f<.debug_info+0x0031828b>
DW_AT_external yes
DW_AT_decl_file 0x00000001 /src/cpython/Python/pylifecycle.c
DW_AT_decl_line 0x00000066
DW_AT_location len 0x0005: 03b0093000: DW_OP_addr 0x003009b0
//...
Progress! DWARF contains a variable named _PyRuntime and gives us its address in memory (DW_AT_location). We can confirm that this is the right variable by looking at the file and line provided by the decl_file and decl_line attributes. Let’s see if we can retrieve its contents from within CPython, to validate the findings. To make it easy on myself, I added a little exported C function in the sys module code (Python/sysmodule.c) to retrieve some useful information:
PyObject* debugme(PyObject*, PyObject*)
{
printf("DEBUG ME!\n");
_PyRuntimeState *rt = &_PyRuntime;
printf("Address of _PyRuntime: %p\n", rt);
printf("Size of _PyRuntimeState: %d\n", sizeof(_PyRuntimeState));
printf("Address of gilstate: %p\n", &rt->gilstate);
printf("Address of tstate_current: %p\n", &rt->gilstate.tstate_current);
Py_RETURN_NONE;
}
Rebuilding CPython and running it:
Python 3.11.4+ (heads/dev-dirty:c9eb99e348, Jul 4 2023, 15:40:38) [Clang 15.0.7 ] on wasi
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.debugme()
DEBUG ME!
Address of _PyRuntime: 0x3009e0
Size of _PyRuntimeState: 85152
Address of gilstate: 0x300b44
Address of tstate_current: 0x300b48
>>>
Good to confirm that this is indeed the address in linear memory of the global _PyRuntime value. We now know that:
gilstateis0x300b44 - 0x3009e0 = 356bytes into the_PyRuntimestruct.tstate_currentis0x300b48 - 0x300b44 = 4bytes intogilstate.
So effectively, for this version of Python, the pointer to the current PyThreadState lives at addressof(_PyRuntime) + 356 + 4.
Given we already know how to parse DWARF content and read linear memory, it is reasonably straightforward to implement in wzprof.
Let’s keep tracing print_stack to see what it does once it has a pointer to PyThreadState:
_PyInterpreterFrame *frame = tstate->cframe->current_frame;
It follows pointers from the thread state to the current frame.
It’s a good time to keep in mind that we are operating from outside the Python runtime in this project. The only thing we have at our disposal is the ability to pause the program and read arbitrary addresses in its memory. When clang compiles CPython, it knows the layout of every struct, so generating instructions for the expressions such as tstate->cframe is easy. We need to figure out how to do the same thing but without that intrinsic knowledge of the program’s structure. There are multiple ways of achieving this. We can write a function similar to debugme() above to dump all the struct offsets we need or inspect the DWARF information for struct members’ offsets.
After retrieving the frame pointer, sys__getframe_impl calls _PyFrame_GetFrameObject on that _PyInterpreterFrame*:
/* Gets the PyFrameObject for this frame, lazily
* creating it if necessary.
* Returns a borrowed referennce */
static inline PyFrameObject *_PyFrame_GetFrameObject(_PyInterpreterFrame *frame)
{
assert(!_PyFrame_IsIncomplete(frame));
PyFrameObject *res = frame->frame_obj;
if (res != NULL) {
return res;
}
return _PyFrame_MakeAndSetFrameObject(frame);
}
source: Include/internal/pycore_frame.h
Now that’s a bit worrisome. If the frame_obj pointer is absent, Python creates it. We should not modify the guest memory, so we cannot go down that route. Let’s take a quick peek at how it is created (asserts and comments removed):
PyFrameObject *_PyFrame_MakeAndSetFrameObject(_PyInterpreterFrame *frame)
{
PyObject *error_type, *error_value, *error_traceback;
PyErr_Fetch(&error_type, &error_value, &error_traceback);
PyFrameObject *f = _PyFrame_New_NoTrack(frame->f_code);
if (f == NULL) {
Py_XDECREF(error_type);
Py_XDECREF(error_value);
Py_XDECREF(error_traceback);
return NULL;
}
PyErr_Restore(error_type, error_value, error_traceback);
if (frame->frame_obj) {
f->f_frame = (_PyInterpreterFrame *)f->_f_frame_data;
f->f_frame->owner = FRAME_CLEARED;
f->f_frame->frame_obj = f;
Py_DECREF(f);
return frame->frame_obj;
}
f->f_frame = frame;
frame->frame_obj = f;
return f;
}
source: Python/frame.c
Aside from the error handling, this function really only fills the PyFrameObject with information from the _PyInterpreterFrame. A quick search on the topic did not reveal much about why CPython duplicates the information this way. If you have clues on the topic let me know!
That means we can get away with only using the _PyInterpreterFrame for our purpose. Great! We have a way to get to the top of the interpreter call stack, which is made of _PyInterpreterFrame structs. Let’s look at its definition to make sure it is possible to recursively find the caller frames (walking the stack):
typedef struct _PyInterpreterFrame {
/* "Specials" section */
PyFunctionObject *f_func; /* Strong reference */
PyObject *f_globals; /* Borrowed reference */
PyObject *f_builtins; /* Borrowed reference */
PyObject *f_locals; /* Strong reference, may be NULL */
PyCodeObject *f_code; /* Strong reference */
PyFrameObject *frame_obj; /* Strong reference, may be NULL */
/* Linkage section */
struct _PyInterpreterFrame *previous;
_Py_CODEUNIT *prev_instr;
int stacktop; /* Offset of TOS from localsplus */
bool is_entry; // Whether this is the "root" frame for the current _PyCFrame.
char owner;
/* Locals and stack */
PyObject *localsplus[1];
} _PyInterpreterFrame;
source: Include/internal/pycore_frame.h
There it is, the previous member, which points to another _PyInterpreterFrame.
Now that we have the stack frame, we need to dig into the following operation of print_stack: traceback.extract_stack.
def extract_stack(f=None, limit=None):
"""Extract the raw traceback from the current stack frame.
The return value has the same format as for extract_tb(). The
optional 'f' and 'limit' arguments have the same meaning as for
print_stack(). Each item in the list is a quadruple (filename,
line number, function name, text), and the entries are in order
from oldest to newest stack frame.
"""
if f is None:
f = sys._getframe().f_back
stack = StackSummary.extract(walk_stack(f), limit=limit)
stack.reverse()
return stack
source: Lib/traceback.py
We’ve just covered retrieving the frame, so the next function call is walk_stack:
def walk_stack(f):
"""Walk a stack yielding the frame and line number for each frame.
This will follow f.f_back from the given frame. If no frame is given, the
current stack is used. Usually used with StackSummary.extract.
"""
if f is None:
f = sys._getframe().f_back.f_back.f_back.f_back
while f is not None:
yield f, f.f_lineno
f = f.f_back
source: Lib/traceback.py
That’s pretty good. It confirms the call stack is a linked list that we can follow to the head using the f_back pointer of its elements, or in our case previous because we are dealing with the _PyInterpreterFrame directly.
Symbolization
We need to understand how f_lineno is computed. It is actually a getter function on the PyFrameObject:
static PyObject *frame_getlineno(PyFrameObject *f, void *closure)
{
int lineno = PyFrame_GetLineNumber(f);
if (lineno < 0) {
Py_RETURN_NONE;
}
else {
return PyLong_FromLong(lineno);
}
}
source: Objects/frameobject.c
Digging one more level:
int PyFrame_GetLineNumber(PyFrameObject *f)
{
assert(f != NULL);
if (f->f_lineno != 0) {
return f->f_lineno;
}
else {
return _PyInterpreterFrame_GetLine(f->f_frame);
}
}
source: Objects/frameobject.c
Some caching. Then finally:
int _PyInterpreterFrame_GetLine(_PyInterpreterFrame *frame)
{
int addr = _PyInterpreterFrame_LASTI(frame) * sizeof(_Py_CODEUNIT);
return PyCode_Addr2Line(frame->f_code, addr);
}
source: Python/frame.c
Two things to unpack here. First, it computes an “address” from the frame. Expanding macros:
#define _PyInterpreterFrame_LASTI(IF) \
((int)((IF)->prev_instr - _PyCode_CODE((IF)->f_code)))
#define _PyCode_CODE(CO) ((_Py_CODEUNIT *)(CO)->co_code_adaptive)
typedef uint16_t _Py_CODEUNIT;
sources: pycore_frame.h, code.h:144, code.h:19
So in other words, that address is the distance in bytes from frame->prev_instr and frame->f_code->code_adaptive. f_code is a PyCodeObject* defined in code.h by a macro (preserved comments because I think they are interesting):
#define _PyCode_DEF(SIZE) { \
PyObject_VAR_HEAD \
\
/* Note only the following fields are used in hash and/or comparisons \
* \
* - co_name \
* - co_argcount \
* - co_posonlyargcount \
* - co_kwonlyargcount \
* - co_nlocals \
* - co_stacksize \
* - co_flags \
* - co_firstlineno \
* - co_consts \
* - co_names \
* - co_localsplusnames \
* This is done to preserve the name and line number for tracebacks \
* and debuggers; otherwise, constant de-duplication would collapse \
* identical functions/lambdas defined on different lines. \
*/ \
\
/* These fields are set with provided values on new code objects. */ \
\
/* The hottest fields (in the eval loop) are grouped here at the top. */ \
PyObject *co_consts; /* list (constants used) */ \
PyObject *co_names; /* list of strings (names used) */ \
PyObject *co_exceptiontable; /* Byte string encoding exception handling \
table */ \
int co_flags; /* CO_..., see below */ \
short co_warmup; /* Warmup counter for quickening */ \
short _co_linearray_entry_size; /* Size of each entry in _co_linearray */ \
\
/* The rest are not so impactful on performance. */ \
int co_argcount; /* #arguments, except *args */ \
int co_posonlyargcount; /* #positional only arguments */ \
int co_kwonlyargcount; /* #keyword only arguments */ \
int co_stacksize; /* #entries needed for evaluation stack */ \
int co_firstlineno; /* first source line number */ \
\
/* redundant values (derived from co_localsplusnames and \
co_localspluskinds) */ \
int co_nlocalsplus; /* number of local + cell + free variables \
*/ \
int co_nlocals; /* number of local variables */ \
int co_nplaincellvars; /* number of non-arg cell variables */ \
int co_ncellvars; /* total number of cell variables */ \
int co_nfreevars; /* number of free variables */ \
\
PyObject *co_localsplusnames; /* tuple mapping offsets to names */ \
PyObject *co_localspluskinds; /* Bytes mapping to local kinds (one byte \
per variable) */ \
PyObject *co_filename; /* unicode (where it was loaded from) */ \
PyObject *co_name; /* unicode (name, for reference) */ \
PyObject *co_qualname; /* unicode (qualname, for reference) */ \
PyObject *co_linetable; /* bytes object that holds location info */ \
PyObject *co_weakreflist; /* to support weakrefs to code objects */ \
PyObject *_co_code; /* cached co_code object/attribute */ \
char *_co_linearray; /* array of line offsets */ \
int _co_firsttraceable; /* index of first traceable instruction */ \
/* Scratch space for extra data relating to the code object. \
Type is a void* to keep the format private in codeobject.c to force \
people to go through the proper APIs. */ \
void *co_extra; \
char co_code_adaptive[(SIZE)]; \
}
/* Bytecode object */
struct PyCodeObject _PyCode_DEF(1);
source: Include/cpython/code.h
The PyCodeObject starts with a header (the struct defined above) and is immediately followed by the byte code of the function it represents. Now looking at the next function call:
return PyCode_Addr2Line(frame->f_code, addr);
Exciting! It means we are close to the end: this function will return the line number of the instruction the frame is stopped at. In Objects/codeobject.c:
int PyCode_Addr2Line(PyCodeObject *co, int addrq)
{
if (addrq < 0) {
return co->co_firstlineno;
}
assert(addrq >= 0 && addrq < _PyCode_NBYTES(co));
if (co->_co_linearray) {
return _PyCode_LineNumberFromArray(co, addrq / sizeof(_Py_CODEUNIT));
}
PyCodeAddressRange bounds;
_PyCode_InitAddressRange(co, &bounds);
return _PyCode_CheckLineNumber(addrq, &bounds);
}
source: Objects/codeobject.c
For the sake of this blog post, we’ll assume that co->_co_linearray is always NULL (it’s the older way of storing line numbers). So there it is. Python stores a pointer to the current byte code in each frame, and that byte code needs to be resolved into an actual line number using what looks like a line table. Same thing as Go!
The actual resolution is performed by _PyCode_CheckLineNumber:
/* Update *bounds to describe the first and one-past-the-last instructions in
the same line as lasti. Return the number of that line, or -1 if lasti is
out of bounds. */
int _PyCode_CheckLineNumber(int lasti, PyCodeAddressRange *bounds)
{
while (bounds->ar_end <= lasti) {
if (!_PyLineTable_NextAddressRange(bounds)) {
return -1;
}
}
while (bounds->ar_start > lasti) {
if (!_PyLineTable_PreviousAddressRange(bounds)) {
return -1;
}
}
return bounds->ar_line;
}
source: Objects/codeobject.c
bounds is initialized in _PyCode_InitAddressRange. It contains two pointers: one to the beginning of the code section and the other to the end of it. Then the code iterates to narrow down to the instructions surrounding the given address and returns the line number they correspond to. Let’s look at _PyLineTable_NextAddressRange (removing comments, asserts, and recording functions for clarity):
int _PyLineTable_NextAddressRange(PyCodeAddressRange *range)
{
if (at_end(range)) {
return 0;
}
advance(range);
return 1;
}
static inline int at_end(PyCodeAddressRange *bounds) {
return bounds->opaque.lo_next >= bounds->opaque.limit;
}
static void advance(PyCodeAddressRange *bounds)
{
bounds->opaque.computed_line += get_line_delta(bounds->opaque.lo_next);
if (is_no_line_marker(*bounds->opaque.lo_next)) {
bounds->ar_line = -1;
}
else {
bounds->ar_line = bounds->opaque.computed_line;
}
bounds->ar_start = bounds->ar_end;
bounds->ar_end += next_code_delta(bounds);
do {
bounds->opaque.lo_next++;
} while (bounds->opaque.lo_next < bounds->opaque.limit &&
((*bounds->opaque.lo_next) & 128) == 0);
}
static int get_line_delta(const uint8_t *ptr)
{
int code = ((*ptr) >> 3) & 15;
switch (code) {
case PY_CODE_LOCATION_INFO_NONE:
return 0;
case PY_CODE_LOCATION_INFO_NO_COLUMNS:
case PY_CODE_LOCATION_INFO_LONG:
return scan_signed_varint(ptr+1);
case PY_CODE_LOCATION_INFO_ONE_LINE0:
return 0;
case PY_CODE_LOCATION_INFO_ONE_LINE1:
return 1;
case PY_CODE_LOCATION_INFO_ONE_LINE2:
return 2;
default:
/* Same line */
return 0;
}
}
static int next_code_delta(PyCodeAddressRange *bounds)
{
return (((*bounds->opaque.lo_next) & 7) + 1) * sizeof(_Py_CODEUNIT);
}
static int is_no_line_marker(uint8_t b)
{
return (b >> 3) == 0x1f;
}
source: Objects/codeobject.c
It’s a lot to take in, but that is the final piece! The program scans a line table structure that tells how to compute the original source file position for a given entry in the byte code. That line table is an array of bytes, where each byte needs its bits to be interpreted as such:
Bits 0-2: the next byte code delta. They represent how many instructions in the byte code this entry covers.
Bits 3-6: the “code”. It’s the enum in get_line_delta. It explains what to do with the current line counter. Options are:
- No change.
- Increment by 1.
- Increment by 2.
- Increment by some signed varint just following this byte.
Bit 7: set if this byte is the first byte of the entry.
An entry is one byte, except when it increments the line count by other than 0, 1, or 2, as a signed variable-length integer follows it. The bytes of the varint therefore never have the 7th-bit set. Technically those entries can also contain 3 additional varints (how many lines the instruction cover, first and last column) but let’s keep it simple.
To sum it up, the line table decoding starts at the beginning of the code section and at the beginning of the line table, and a line counter is set to co_firstlineno. It decodes each successive entry in the line table, telling it: how much to increase (or decrease!) the line number and how many bytes it needs to move forward in the byte code. Repeat until the desired position in the byte code is reached, and voilà, the line number!
As a side note, the signed var int encoding uses only 7 bits instead of 8 because the line table uses the last bit to indicate whether this is the first byte of an entry. It seems wasteful to me because varints already have the notion of continuation bit, but there must be a reason. If anyone knows why it’s necessary, let me know!
We did the hard part. We have stack walking, and we know how to compute the line number of a given stack frame’s current byte code address.
For full symbolization, we also want to know the name of the function being executed and which source file it comes from. Looking back at the PyCodeObject definition, it has two aptly named members: co_filename and co_name.
However, in wzprof we don’t have access to the PyObject* manipulation functions, so we need to understand how to get the bytes of a Unicode string from a PyObject*. This could be another deep dive into how Python stores and manipulates string objects, but for now, we need to get back to the surface to breathe some fresh air (if you still have some in the tank, look at PyUnicode_AsUTF8AndSize from the unicode module).
Wrap up
Now we understand how CPython represents the call stack of the program it is executing and how it stores the line numbers of those functions. The next step would be to consider Python C extensions. Many popular Python packages rely on C extensions to implement some features (often because of speed). Being able to provide profiling into the execution of those functions and the interpreter at the same time would be powerful for users of such libraries.
The support for CPython 3.11 symbolization and stack walking, as described in this post, has landed in wzprof 0.2.0 (patch). Check it out, and let us know if you have any feedback!
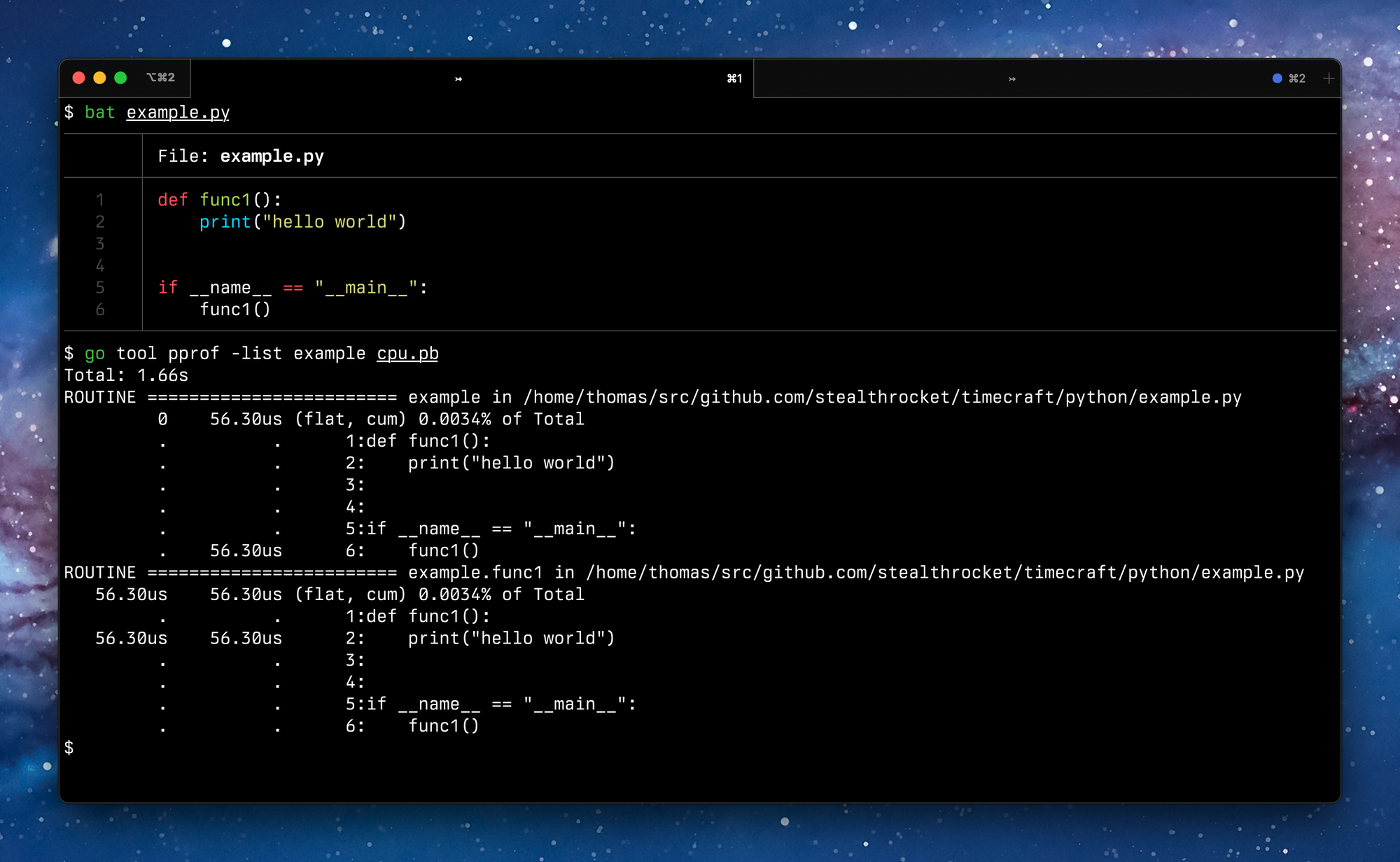
I hope you have found this dive into the internals of CPython as interesting as I did. I am still surprised by how approachable the internals of a relatively old code base as widely used as Python is. It was my first real foray into CPython. If you see any inaccuracy or want to chat about this topic some more, join our Discord server. If you are interested in how the symbolization and stack walking for Golang work, take a look at the original pull request and Twitter thread.