Your async workflow needs an upgrade, not another queue
Chris O'Hara | Mar 26th, 2024
Dispatch is a cloud service for developing reliable distributed systems. For an introduction, check out or previous blog post: Genesis of a new programming model
Who hasn’t built a system that exports data to a third-party service?
Many times in my career I’ve had to write workflows like this one, which exports user data to Saleforce:
def export_users_to_salesforce(db, instance_url, access_token):
with db.cursor() as users:
users.execute("SELECT id, first_name, last_name, email FROM users")
for user in users:
send_user_to_salesforce(user, instance_url, access_token)
def send_user_to_salesforce(user, instance_url, access_token):
url = f"{instance_url}/services/data/v52.0/sobjects/User"
headers = {"Authorization": f"Bearer {access_token}"}
data = {
"FirstName": user["first_name"],
"LastName": user["last_name"],
"Email": user["email"],
}
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
return response
Although workflows like this are quick to write, they’re not production-ready. Everything runs smoothly for a while, handling the expected volume. But then, one day, it encounters unexpected resistance. The data volume crosses a threshold, causing API rate limits to kick in. Or the API undergoes maintenance, leading to temporary downtime.
Asynchronous work queues offer a lifeline in these situations. By acting as a buffer in front of the third-party API, queues help workflows gracefully handle temporary outages and fluctuations in capacity.
Unfortunately queues aren’t a silver bullet — while they solve some problems, they also introduce new ones. Luckily, there’s a better way! In this blog post, we’ll explore the limitations of queues and the solution for building robust and scalable integrations. By the end, you’ll be armed with the knowledge and tools required to ensure your data flows smoothly even when things get bumpy.
Resilient Integrations using Queues
Before diving into the issues that plague queues, let’s talk about the benefits.
Queues for asynchronous work are an established pattern when building distributed systems. The primary benefit of a queue is the ability to decouple producers from consumers/processors. Queues act as a buffer; producers aren’t blocked while waiting for long-running work to finish, and consumers can take on work if/when they’re ready. Queues provide additional durability for work, allowing both producers and consumers to crash without causing data loss. Queues allow producers and consumers/processors to be scaled independently.
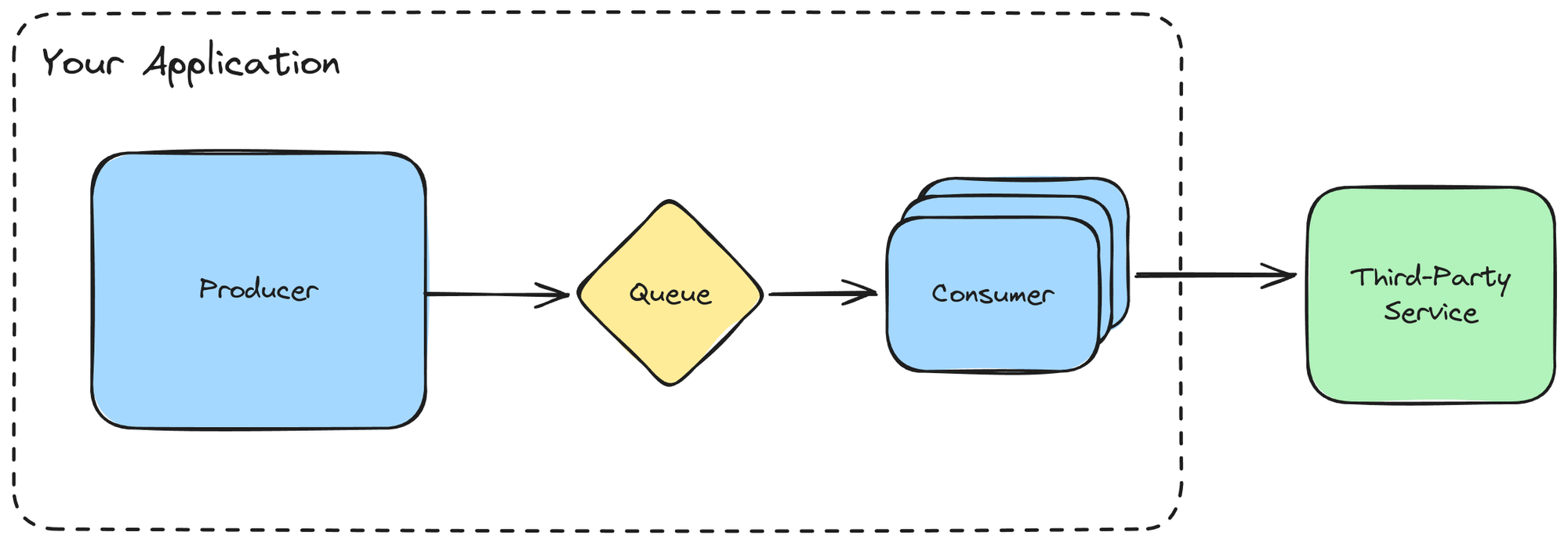
Queues are a natural fit for data integrations. Our example integration is simply split in two, the producer and the consumer:
# Producer:
def export_users_to_salesforce(db, queue):
with db.cursor() as users:
users.execute("SELECT id, first_name, last_name, email FROM users")
for user in users:
queue.send_message(user)
def consumer(queue, instance_url, access_token):
while True:
message = queue.receive_message()
user = message.contents
try:
send_user_to_salesforce(user, instance_url, access_token)
except:
queue.requeue_message(message.id) # retry later
else:
queue.delete_message(message.id) # send is complete
This is more resilient to failure! If something goes wrong, a consumer can move on and try another request. The failing message will be (re)delivered to a consumer sometime later, allowing the request to be retried.
There are many dimensions to consider when choosing a queue. Some queues are highly durable, offering built-in persistence to disk and possibly replication across nodes. Some queues are tuned for throughput while others primarily target low-latency use cases. Some queues maintain ordering between messages while others don’t. Some queues are serverless, some are offered as managed services, and some must be hosted and scaled manually. Some queues are designed to be as simple as possible, while others give developers control over many aspects of message storage, replication and delivery.
Each of the major clouds offers a proprietary queue. Some also offer managed versions of open source queues. For example, AWS offers its proprietary Simple Queue Service (SQS) and Kinesis queues, and also has a fully-managed Kafka offering (MSK).
The Hidden Costs of Queues
There are obvious costs involved when using queues. Decoupling producers from consumers offers many benefits, but this requires extra infrastructure (in terms of the queue itself, and the separate services required for producers and consumers). Extra infrastructure means extra operating costs and extra complexity. While managed and serverless offerings in the cloud help to minimize the infrastructure footprint, they come with additional per-unit costs.
These explicit costs are usually outweighed by the benefits that queues bring, which is why the asynchronous work queue pattern is so ubiquitous. However, we often gloss over the insidious hidden costs of queues that can change the equation.
Hidden Trade-offs
Queues are usually touted as having excellent durability and performance (throughput and/or latency) characteristics, while being simple and low cost to build with and to operate.
For example, NSQ is easy to set up and operate, and has good performance characteristics. Unfortunately though, the queue is not durable by default and data may occasionally be lost. Redis is another example of an in-memory queue that has the same trade-off. Although additional durability can be configured in terms of local disk persistence, messages can still be lost when hardware fails in the cloud. A queue that potentially loses data isn’t much good, and developers shopping around for queues may be surprised when this important detail is omitted from the features listed upfront. Worse, durability issues can go unnoticed for a long time.
Queues that support replication, such as Kafka, are harder to set up. It’s necessary to configure and maintain a quorom, and capacity planning may be required to determine the right number of brokers and partitions. Some companies have entire teams devoted to setting up and operating these queues. Although managed offerings in the cloud alleviate some of these concerns, the trade-off there is additional operating costs. Even with replication enabled for extra durability, it’s still easy for developers to accidentally take a less durable write path (for example, avoiding write “acks” from all replicas). This may occur in the pursuit of additional performance, or as a result of a configuration error.
Surprising Limits
Similarly, queues may have very liberal limits in one or more dimensions and then have overly restrictive limits that can make them unsuitable for certain use cases.
As an example, the SQS documentation flexes that it can support “a nearly unlimited number of API calls per second” when sending and receiving messages. While this sounds impressive, SQS is limited to only 120,000 in-flight messages before it starts rejecting new messages. This limit is hidden away in the documentation. A developer may only find out about it when their production system hits the ceiling for the first time!
In the context of data integrations (and third-party services that go down or rate-limit temporarily) 120,000 pending requests is not unlikely. The official AWS recommendation is to “increase the number of queues you use to process your messages”. While this solution may be good for cloud providers, for users, more queues mean greater costs and complexity. Partitioning work across multiple queues isn’t a quick fix either; it’s the last thing a developer investigating a failing production system wants to see after hours.
Limited Control After Failure
Queues typically fall into two buckets. Unordered queues, including SQS and NSQ, allow messages to be processed and deleted individually. It’s easy to retry failling operations — such as a rate-limited request — with these queues:
def consumer(queue, instance_url, access_token):
while True:
message = queue.receive_message()
user = message.contents
try:
send_user_to_salesforce(user, instance_url, access_token)
except:
queue.requeue_message(message.id) # retry later
else:
queue.delete_message(message.id) # send is complete
We’re taught to incorporate backoff between attempts to prevent overloading the service downstream. We may have also been exposed to advanced techniques like circuit breakers and adaptive concurrency control. Some queues (e.g. NSQ) support adding a delay before messages are requeued, while others (e.g. SQS) do not. No queues natively support circuit breakers or concurrency control, and retrofitting them on to a queue requires extra services and secondary storage, increasing costs and complexity. At best, queues provide only rudimentary control over the rate at which messages are processed, and when messages are redelivered after failure.
Ordered queues on the other hand, such as Kafka, Kinesis and SQS (with its FIFO variant), have a worse problem: head-of-line blocking. These queues are chosen for their desirable performance and durability characteristics, but they have a restrictive consumer API that makes failure handling and retries harder.
When message processing fails — for example, a request fails due to a rate-limiting error — the consumer does not have a way to requeue the message and move on to processing another. To make progress, the consumer must either skip the message, retry the processing inline, or write the message to another location (e.g. an overflow or dead-letter queue):
- Skipping the message in order to make progress essentially means data loss, e.g. a rate-limited request is never successfully sent downstream.
- Retrying inline may limit concurrency and grind throughput to a halt. This is especially problematic when the queues contain data from multiple tenants, causing implicit coupling between unrelated messages.
- Using extra queues to hold temporary and permanent failures adds costs and complexity, and doesn’t really solve the issue; what if a consumer for one of the additional queues itself sees a failure? are more queues and consumers needed in order to retry the failing retry?
Various solutions to the head-of-line blocking problem have been devised over time. For example, Uber created their Consumer Proxy. While these solutions work in limited scenarios, they bring additional operating costs and complexity to the table, particularly in the context of data integrations.
Unsuitable for Workflows
The problems compound when users try to build asynchronous workflows on top of queues. Imagine a data integration where you need to make multiple requests in a specific order, using the outputs of previous steps to derive inputs for subsequent requests. Although queues store the workflow input durably, they don’t track progress of the workflow. If failure occurs, a consumer can do no better than retrying individual operations inline or, later, restarting the workflow from the beginning.
Workflow orchestrators, such as Apache Airflow and AWS Step Functions, were designed to help here, but they add an additional layer of cost and complexity. They force developers to learn DSLs and structure their workflows and state a certain way. Like with queues, it’s not uncommon to find entire teams devoted to operating them at larger companies.
Wouldn’t it be nice if there was a way to build durable workflows without the explosion in complexity?
Ditch the Queue
Having been down this path before while scaling Segment.com’s data integrations infrastructure, we wanted to build the next generation of tools for developers to avoid these issues.
Dispatch is a cloud service that makes building scalable & reliable production systems a breeze. It’s the system we wish we had back then. It allows you to ditch the queue and its hidden costs, and go back to writing simple code.
Here’s the example integration using Dispatch:
def export_users_to_salesforce(db, instance_url, access_token):
with db.cursor() as users:
users.execute("SELECT id, first_name, last_name, email FROM users")
for user in users:
send_user_to_salesforce.dispatch(user, instance_url, access_token)
@dispatch.function
def send_user_to_salesforce(user, instance_url, access_token):
...
The only change from the original integration is we’ve added a @dispatch.function annotation and changed how the function is called .dispatch(...). Your integration is now a scalable and reliable distributed system! There are no queues to deploy and configure, and no need for manual failure handling.
Dispatch has a distributed scheduler that drives execution to completion. It automatically adapts to changes in load, capacity, latency and failure rates over time. It also keeps track of progress within a function, allowing workflows to be expressed with nothing more than regular programming language constructs and control flow. Not only can you ditch the queue, you can ditch the orchestrator too!
Writing an integration with a third-party service is a rite of passage for developers. We quickly find, however, that our simple workflows don’t hold up in the real world where capacity and load fluctuate, and where timeouts and network failures occur often. Asynchronous work queues to the rescue! we think. Indeed, queues add reliability and can help through the next phase of growth, however the cracks soon start to appear in terms of complexity and costs, both explicit and hidden.
It doesn’t have to be this way. Dispatch allows developers to go back to writing simple code. It handles the hard parts of distributed systems so that developers can focus on the important things. Stop wrangling with your integrations and queues and try Dispatch today!
Sign up to the developer preview for free today at https://console.dispatch.run and follow us on Twitter and Discord for updates.