Distributed Coroutines: a new primitive soon in every developer’s toolkit
Chris O'Hara | Mar 7th, 2024
Dispatch is a cloud service for developing reliable distributed systems. For an introduction, check out or previous blog post: Genesis of a new programming model
Traditional workflow orchestration frameworks can feel like a double-edged sword. Sure, they promise fault tolerance, but at what cost? Complexity skyrockets and applications are constrained to fit within a rigid scaffolding, sacrificing much of the flexibility and expressiveness of programming.
When we designed Dispatch, we knew we had to overcome these limitations – could we make durability a superpower baked right into the code itself?
—
At the heart of Dispatch are Distributed Coroutines, a novel primitive to power the next generation of distributed applications. What are Distributed Coroutines and why are they useful? Let’s find out!
Coroutines are Everywhere
Coroutines are everywhere, but they’re often disguised. Async functions, generators, and goroutines are a few examples of coroutines that developers may be familiar with.
Coroutines look like regular functions. The difference is that they can include a type of non-local control flow that allows them to yield control to another part of the program. Coroutines are suspended at the point they yield and can later be resumed from the same location.
Coroutines are functions that can be suspended and resumed.
Usually, functions only communicate with other functions via input arguments and return values. With yield points, coroutines gain an extra way to communicate.
def coroutine1():
for i in range(3):
yield i
async def coroutine2():
await sleep(10)
With the ability to yield control to and communicate with other parts of the program, coroutines open up new possibilities for execution.
Coroutines are a flexible primitive, and typically used to implement higher level programming constructs. Let’s dive into the most common applications: iterators and concurrency.
Use #1: Push-based Iterators
Coroutines can be used to build push-based iterators that drive iteration and “push” items to their caller. Python generators are the quintessential example of this pattern. This is in contrast to pull-based iterators, where the caller drives iteration and has to “pull” items out.
Push-based iterators are spreading across programming languages, for example generators were added to JavaScript, and the latest Go version (1.22) has an experimental range-over-func feature that provides the same push semantics.
Here’s an example of push and pull-based iterators in Python:
def PushIterator(n):
i = 0
while i < n:
yield i
i += 1
class PullIterator:
def __init__(self, n):
self.i = 0
self.n = n
def __iter__(self):
return self
def __next__(self):
if self.i >= self.n:
raise StopIteration
i = self.i
self.i += 1
return i
print(list(PushIterator(3)) # => [0, 1, 2]
print(list(PullIterator(3)) # => [0, 1, 2]
Notice how the push-based iterator uses regular variables and control flow when preparing items. They tend to be shorter and clearer than their equivalent pull-based iterators.
Coroutines allow developers to consolidate code, state and control flow.
Complexity arises when we’re forced to split these interrelated concerns across components & dependencies. In the example above, control flow and state are spread across methods in a class. In a production system, state is spread across databases, queues and caches, and code and control flow is spread across microservices and orchestrators.
Could coroutines be used to tame the complexity of distributed systems?
Use #2: Lightweight Concurrency
Coroutines can be paired with a runtime scheduler that drives the execution of one or more coroutines, suspending them at operations that would typically block execution of a thread, such as performing I/O or using timers. The scheduler coordinates these operations, and then resumes suspended coroutines when the I/O or timer results are ready.
While coroutines are suspended, the scheduler can execute other pending coroutines. Although only one coroutine can be executing at a time (per thread), the scheduler interleaves the execution of many coroutines in order to provide concurrency.
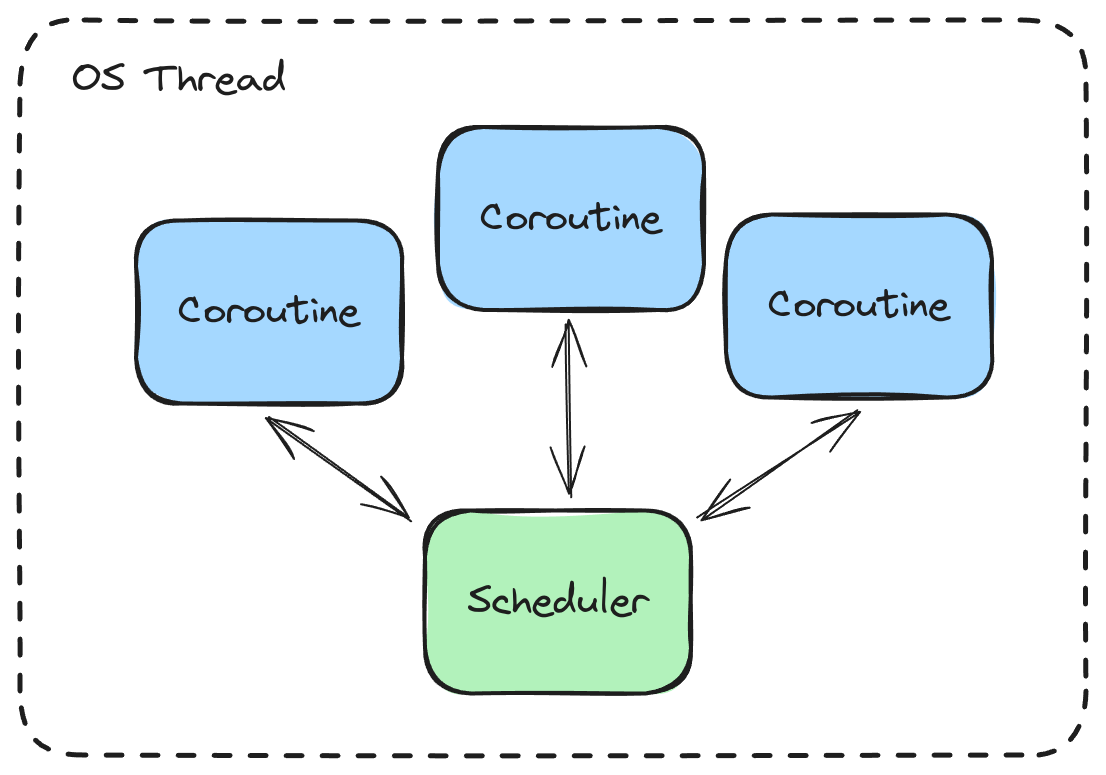
Python’s asyncio library, Go with its built-in goroutine scheduler, and async Rust with the Tokio scheduler are all examples of this pattern.
The pattern has gained popularity in modern languages and runtimes for a few reasons. Coroutines can be suspended and resumed without the developer changing their function’s state or control flow, which makes the software simpler to read and write. The scheduler has a bird’s-eye view of the coroutines that are executing; not only can it perform operations (such as I/O) on their behalf, it can make intelligent scheduling decisions for many coroutines at once.
Could we scale this coroutine<>scheduler model up to reap similar benefits in a distributed system?
Distributed Coroutines
Distributed coroutines are functions that can be suspended, serialized and resumed in another process.
Distributed Coroutines can be serialized into a byte array when suspended. The byte array can be transferred across the network, and stored on disk or in a database. Later, the bytes can be returned to an instance of the application and deserialized to resume the coroutine from where it left off.
The serialized representation contains two key pieces of information. The first is the location that the coroutine was suspended at, which is required in order to resume the coroutine from the same place. The second is the state of the coroutine, which means capturing the contents of the variables that are in scope.
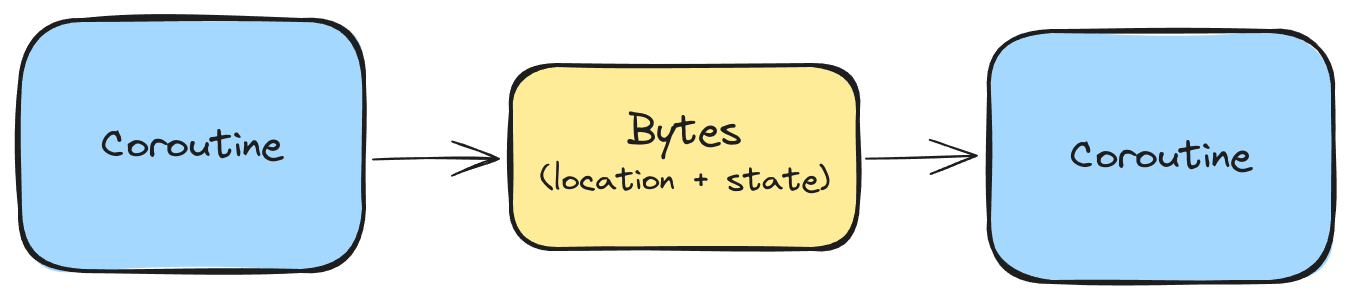
Here’s an example coroutine that yields 3 times:
def mycoroutine():
i = 0
while i < 3:
yield i
i += 1
print(list(mycoroutine()) # => [0, 1, 2]
Here’s the same coroutine annotated with a (pseudo) location:
def mycoroutine():
i = 0 # location 1
while i < 3: # location 2
yield i # location 3 (yield point)
i += 1 # location 4
We can unroll the loop to show how state changes over time:
def mycoroutine():
i = 0
yield i # state: i=0
i += 1
yield i # state: i=1
i += 1
yield i # state: i=2
i += 1
If this were a Durable Coroutine and we were serializing it at its yield points, the serialized representation may look like this:
-
{location:3,state:{i:0}} -
{location:3,state:{i:1}} -
{location:3,state:{i:2}}This example highlights what needs to be serialized but glosses over many important details. In part 2 of this series, we’ll dive into a real implementation in the Dispatch SDK for Python.
Now, let’s dive into the use cases of Distributed Coroutines!
Durable Execution
When building production systems we need to consider what happens when processes crash or restart, since application state residing in memory is lost. Processes could crash due to bugs, hardware failures, or other exceptional circumstances, and they need to be restarted in order to release a new feature or bug fix.
Execution in this fallible environment is fundamentally volatile.
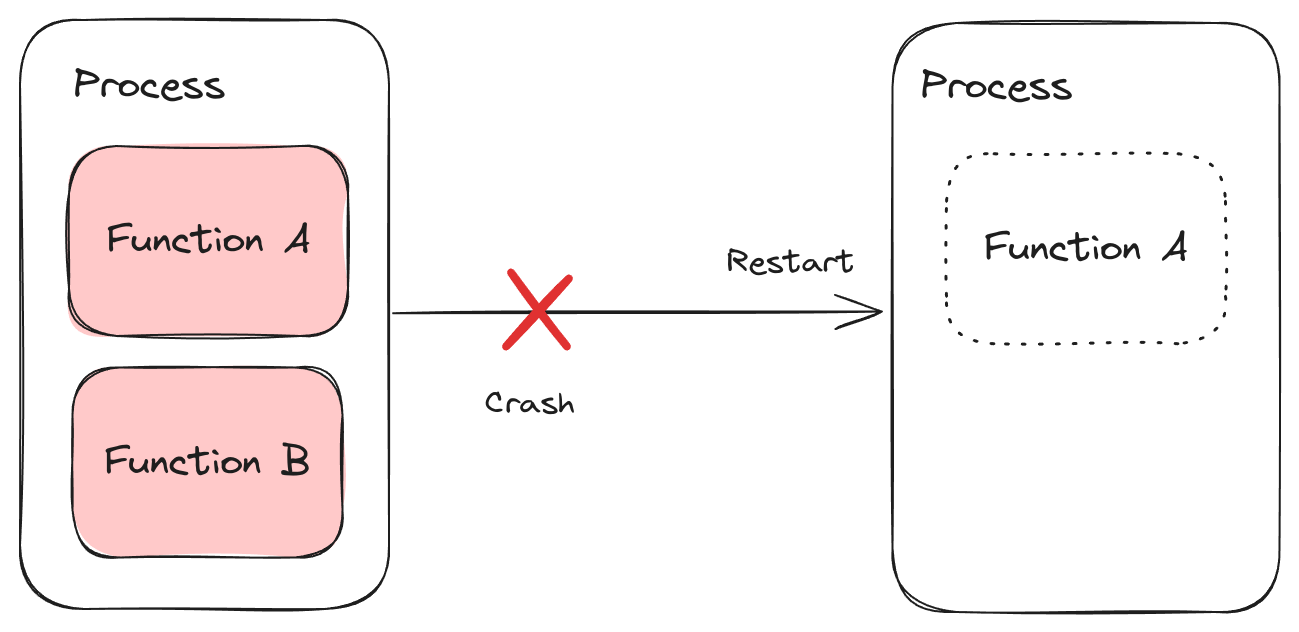
A more durable medium — such as a local disk, a database, or cloud storage — might be required for state so that it isn’t lost in the event of a crash or restart.
Splitting code and state causes a considerable jump in complexity and failure modes. A cache may be required to alleviate performance issues. Code and state must be migrated independently, requiring database migrations, possibly with cache invalidation. The failure modes multiply in a distributed system where each service has its own state spread across private databases, queues and caches.
There’s an immense jump in complexity required to code around volatility.
Durable Execution is the solution to these problems. We wouldn’t need so much infrastructure and complexity if we didn’t have to code around volatility.
Distributed Coroutines are, by design, decoupled from the process in which they were running. Their location and state can be captured and stored durably at yield points. If a process crashes or restarts, the coroutine can be moved to a new process — potentially on another node — and then resumed.
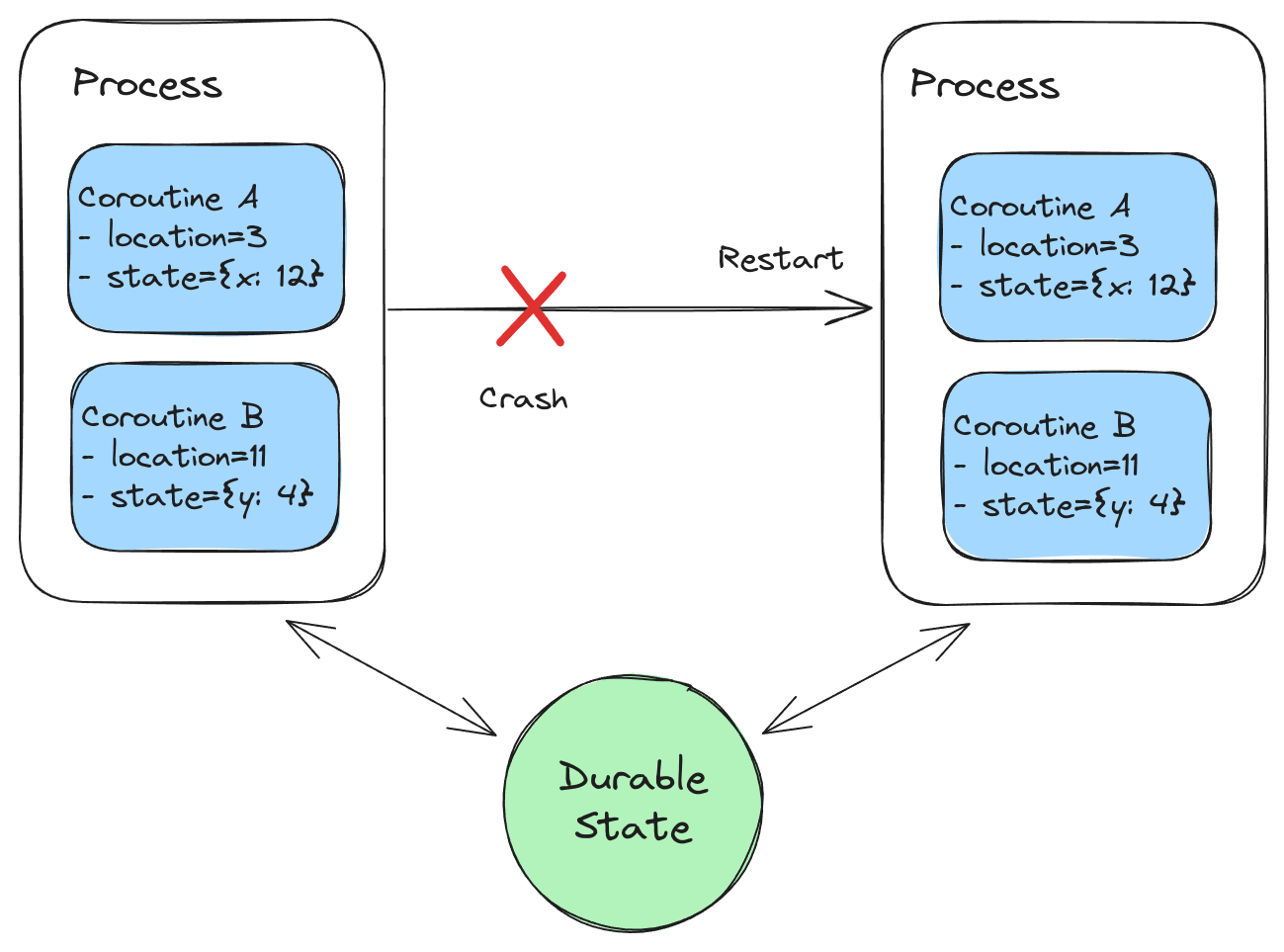
Long-running Functions
Distributed Coroutines enable long-running functions that would be prohibitively expensive to run on a compute service such as AWS Lambda:
async def mycoroutine():
await operationA()
await sleep(24 * 60 * 60) # wait 1 day
await operationB()
A traditional compute service would charge for the total execution time, even if the coroutine was asleep or waiting on I/O for most of it. It might not be able to keep a process running for long enough to complete such a long-running function, and progress is lost if the process crashes.
A Distributed Coroutine doesn’t need to run inside a process while its sleeping or waiting for an operation to complete. It can be serialized and stored offline during this period, without incurring any compute costs. It can be resumed — just at the right time — in a different process than the one it was suspended in, and its progress is preserved.
Workflow-As-Code
Composing operations in code, such as sending emails and storing data in databases, is simple and intuitive:
def workflow():
emails = find_active_user_emails()
results = []
for email in emails:
result = send_email(email)
results.append(result)
store_results_in_database(results)
Unfortunately code like this isn’t suitable for a production system. It sends only one email at a time, which could be too slow depending on the total number of emails. It doesn’t gracefully handle failure. The whole workflow might fail if any one operation fails. The intermediate results could be lost if the process running the function crashes or restarts.
Workflow Orchestrators, such as Apache Airflow and AWS Step Functions, were created to handle this extra complexity, but these tools only shift the problems. They force developers into an unintuitive form of software development, asking them to learn DSLs, structure their state a particular way, and define static graphs of execution in advance. They require extra infrastructure, have their own scale & reliability edge cases, and can be prohibitively costly at a certain scale. Some companies have whole teams devoted to operating a workflow orchestrator and keeping the lights on!
Distributed coroutines allow developers to go back to writing workflows using simple code and control flow. We can express our workflow operations, state and control flow in simple code, and delegate the scheduling of those operations, and the management of state, to a scheduler.
Distributed Scheduling
Coroutines can be paired with a local scheduler to orchestrate their execution within a process.
Distributed coroutines can be paired with a distributed scheduler to orchestrate their execution across processes and nodes.
With a local scheduler, coroutines yield to delegate operations such as I/O and timers to the scheduler, and to allow other coroutines to run. With a distributed scheduler, Distributed Coroutines yield to the scheduler so that it can checkpoint state and intelligently choose when and where to resume execution.
Dispatch has a distributed scheduler that coordinates the execution of Distributed Coroutines.
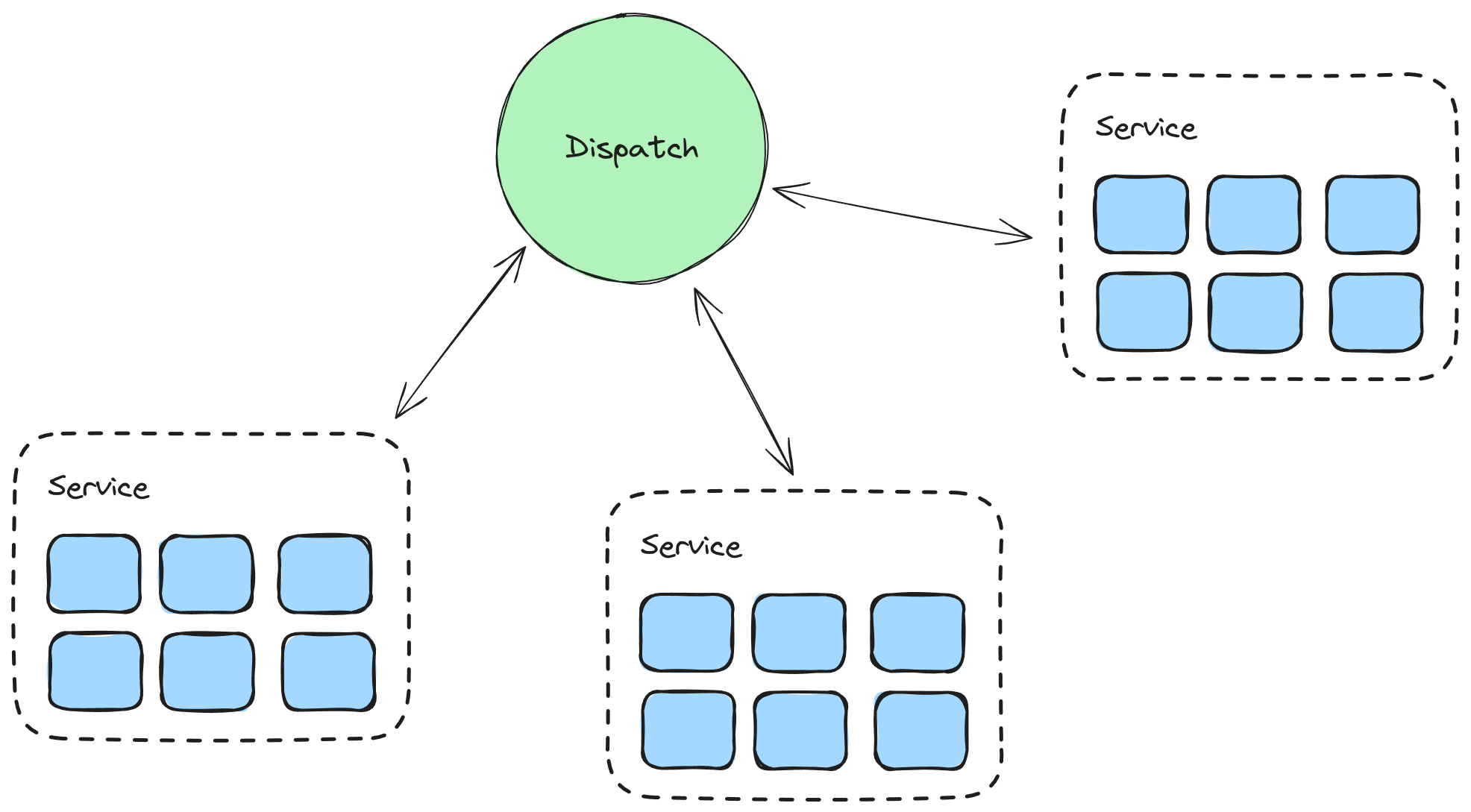
Dispatch can retry failing operations because it has checkpoints to rollback to. Developers no longer have to manually retry failing operations, and deal with unintended side effects (such as load amplification) by incorporating backoff and circuit breakers.
Dispatch manages the execution of many Distributed Coroutines, so it has a bird’s-eye view of the system. This allows it to incorporate intelligent scheduling features, such as adaptively managing the execution concurrency of related coroutines using TCP-like congestion control algorithms. Developers no longer have to worry about transient failures, unexpected load spikes, or overloading adjacent systems on retry, because Dispatch adapts to changes in load, capacity, latency and failure rates over time.
The Next Generation of Distributed Systems
That was a lot to take in, so let’s recap!
Coroutines are functions that can be suspended and resumed. Unlike regular functions, coroutines can yield control (and send information back and forth) to another part of the program during execution. Coroutines allow developers to consolidate code, state and control flow. Developers might not even know they’re using coroutines because they often look like regular functions.
Coroutines pair well with a scheduler, which drives the execution of many coroutines and can perform operations on their behalf. Schedulers can resume suspended coroutines at exactly the right time, e.g. when I/O results are ready, or a timer expires. Schedulers have a bird’s-eye view of many coroutines that are concurrently executing, allowing them to incorporate advanced scheduling techniques.
Distributed Coroutines are functions that can be suspended, serialized and resumed in another process. When paired with a distributed scheduler, such as Dispatch, they drastically simplify the creation of scalable and reliable software. They can encode dynamic workflows with nothing more than regular programming language constructs and control flow. Their execution can flow across processes and nodes, freeing developers from having to code around the volatile and fallible components of the system. Developers — freed from the chains of complexity — can go back to focusing on creating value and keeping their users happy.
With this new primitive in our toolkit, we were able to overcome the limitations that we had experience in prior workflow orchestration solutions. If you’re excited to learn more, stay tuned for our next article that will explore the details of the Python implementation of Distributed Coroutines in the dispatch-py SDK.
In the meantime, sign up to the developer preview of Dispatch for free at https://console.dispatch.run to start using it today, and follow us on Twitter and Discord for more updates!