Distributed coroutines with a native Python extension and Dispatch
Chris O'Hara | Mar 15th, 2024
Dispatch is a cloud service for developing reliable distributed systems. For an introduction, check out the announcement blog post: Genesis of a new programming model.
In part 1 of the series, we took a deep dive into Distributed Coroutines, and saw how they’re used by Dispatch:
Coroutines are functions that can be suspended and resumed. Unlike regular functions, coroutines can yield control (and send information back and forth) to another part of the program during execution. Coroutines allow developers to consolidate code, state and control flow. Developers might not even know they’re using coroutines because they often look like regular functions.
Coroutines pair well with a scheduler, which drives the execution of many coroutines and can perform operations on their behalf. Schedulers can resume suspended coroutines at exactly the right time, e.g. when I/O results are ready, or a timer expires. Schedulers have a bird’s-eye view of many coroutines that are concurrently executing, allowing them to incorporate advanced scheduling techniques.
Distributed Coroutines are functions that can be suspended, serialized and resumed in another process. When paired with a distributed scheduler, such as Dispatch, they drastically simplify the creation of scalable and reliable software. They can encode dynamic workflows with nothing more than regular programming language constructs and control flow. Their execution can flow across processes and nodes, freeing developers from having to code around the volatile and fallible components of the system. Developers — freed from the chains of complexity — can go back to focusing on creating value and keeping their users happy.
In this post we’ll look at how Distributed Coroutines are implemented on the client side.
The implementation differs depending on whether the language is compiled or interpreted, and whether it’s statically typed or dynamically typed. In this post we’ll dig into the implementation for Python, a dynamically-typed interpreted language.
Dispatch: Scale & Reliability Made Simple
First, let’s take a look at an example of using Dispatch with Python:
@dispatch.function
def send_email(to: str, subject: str, html: str):
return resend.Email.send({
'to': to,
'subject': subject,
'html': html,
...
})
@dispatch.function
async def notify_users(opid: str, emails: list[str]) -> None:
pending_operations = [send_email(email) for email in emails]
results = await gather(*pending_operations)
await store_results_in_database(results)
The functions above are Distributed Coroutines that describe a dynamic graph of execution — send an email to each email address in a list, then store the results in a database.
Dispatch sends emails in parallel, automatically respecting rate limits and handling transient failures. It suspends and resumes the functions in order to capture and checkpoint state, and to provide intelligent scheduling capabilities. How does it do this? By leveraging the magic of coroutines!
Distributed Coroutines in Python
Python natively supports coroutines, via generators and async functions. These types of coroutines yield control using the yield, yield from and await keywords. Async functions are commonly paired with the asyncio library, which is the local scheduler that drives their execution and handles I/O and timers on their behalf. Python’s async functions are general purpose coroutines, and can be used with an alternative scheduler, such as Dispatch.
Python includes a standard library package – pickle – to simplify Python object serialization. You simply pickle.dumps(obj) to convert an object to bytes, and later pickle.load(bytes) to restore the object. Pickle handles the hard parts of serialization, such as preserving references and cycles when recursively serializing nested objects. Having a standard way to serialize objects has reduced fragmentation in the Python ecosystem, and many standard library components and third-party dependencies are compatible with pickle.
Serializing Coroutines
Unfortunately the two Python features are not compatible; coroutines cannot be serialized.
>>> import pickle
>>> def generator(): yield
>>> pickle.dumps(generator())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: cannot pickle 'generator' object
This feature has been requested and rejected before in CPython, e.g. see https://bugs.python.org/issue1092962. The major blocker is that a coroutine’s internals (bytecode, instruction pointer, stack, etc.) are implementation details that are subject to change. Making coroutines serializable would require backward compatibility for these internal details, which could make it difficult to add Python features or improve its performance in future.
Serializable coroutines have been implemented in Python before. For example, the stackless project had serializable tasklets which could be used as Distributed Coroutines. Unfortunately the project is no longer maintained.
To solve the incompatibility, the Dispatch SDK for Python provides a @dispatch.function decorator for registering coroutines. The decorator wraps instances of coroutines in a container that’s serializable. The container is the missing piece that allows coroutines to be serialized using the pickle library. It uses a CPython extension to expose internal details regarding the state and location of the coroutine, and serializes this information alongside a reference to the coroutine. The extension handles the differences in implementation details across CPython versions, and currently supports version 3.11+.
In the example below, the internal@durable decorator wraps the coroutine in a serializable container:
@durable
def coroutine():
yield 1
yield 2
yield 3
# Run the coroutine to its first yield point.
instance = coroutine()
print(next(instance)) # => 1
# Serialize the coroutine's location and state.
# Note that these bytes can be shipped across the network,
# and stored durably on disk or in a database.
serialized_coroutine: bytes = pickle.dumps(instance)
print(serialized_coroutine) # => b"\x80\x04\x95V<..snip..>\x8c\x06\xff\xffuub.""
# Deserialize the coroutine and run to its next yield point.
# Rather than starting from scratch, it picks up from where it left off.
instance2 = pickle.loads(serialized_coroutine)
print(next(instance2)) # => 2
print(next(instance2)) # => 3
Scheduling Coroutines
The Dispatch SDK includes two components that link everything together.
The first is an integration with a web server, which allows the SDK to receive function calls from Dispatch and to dispatch them to the right function. The SDK ships with a FastAPI integration that makes this a breeze:
app = FastAPI()
dispatch = Dispatch(app)
@dispatch.function
async def my_function():
...
The second major component is a local scheduler for coroutines.
Users of the SDK do not interact with the local scheduler directly. Rather, it’s spawned when a request comes through to either call or resume a coroutine. The request handler finds the associated @dispatch.function and checks whether it’s a coroutine (async function). If so, it spawns an instance of the local scheduler to take over. The local scheduler creates a new instance of the coroutine, deserializes and restores its location and state, then resumes execution. When the coroutine reaches an await point, the local scheduler serializes its location and state and sends it back Dispatch.
The local scheduler enables coroutines to spawn other coroutines. The local scheduler runs nested coroutines concurrently. If one coroutine reaches an await point, the scheduler continues running other coroutines until they all reach an await point. Only then does it serialize the root coroutine, and all nested coroutines, and send the serialized locations and state back to Dispatch. Nested coroutines exist on the stack of the coroutine that spawned them, so the serialized representation resembles a tree.
Dispatch itself is a distributed scheduler, and the Dispatch SDK itself bundles a local scheduler. This multi-level scheduler approach is similar to what you would find in a modern programming language runtime. Python with its asyncio library, or Go with its runtime goroutine scheduler, both expose lightweight schedulers for coroutines that sit on top of the operating system’s scheduler for threads. The upper scheduler can run coroutines and aggregate their I/O and timer operations before yielding to the OS scheduler to coordinate the work. Similarly, the Dispatch SDK runs coroutines in-memory, before yielding to the distributed Dispatch scheduler to coordinate the work (which requires a more expensive network roundtrip).
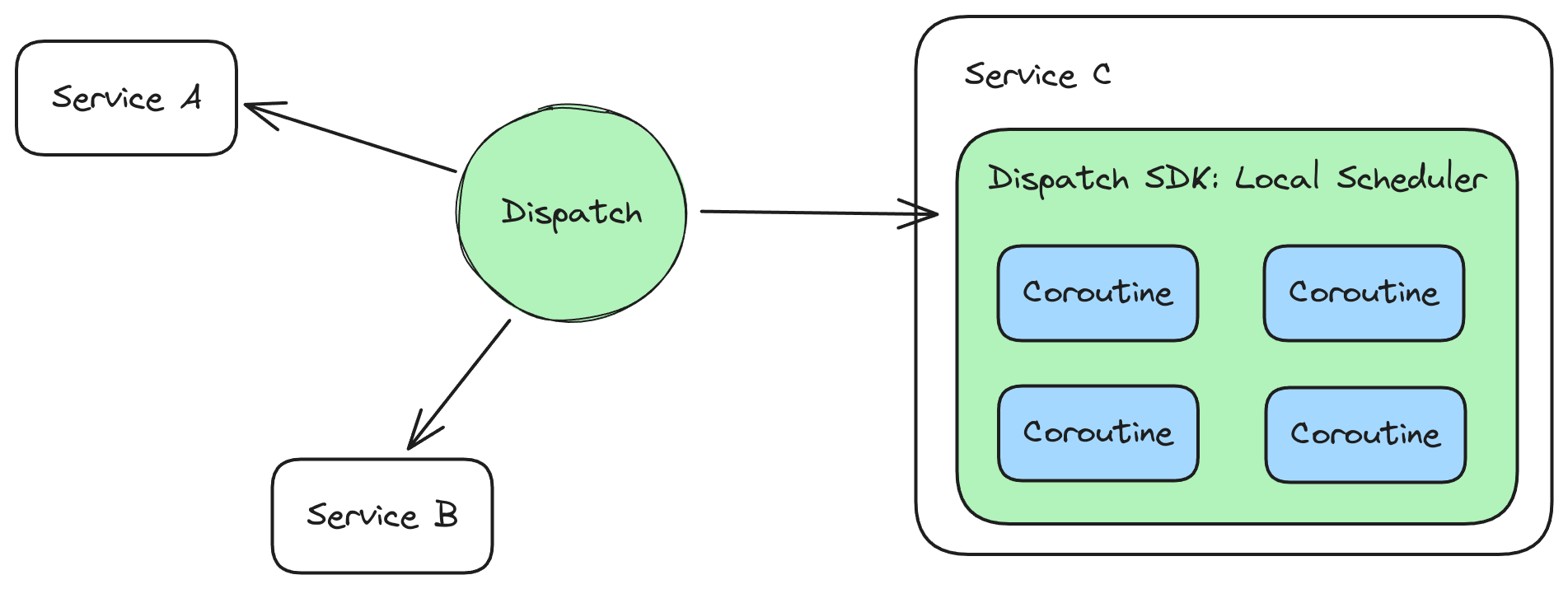
Serialization Challenges
Serializing coroutines and shipping them across processes and nodes comes with an interesting set of engineering challenges. Read the sections below for a summary of the issues, and the solutions and trade-offs provided by Dispatch.
File & Network Handles
There are objects, such as a database connections and open files, that cannot be serialized because they contain handles relevant only to a particular process. The handles cannot be serialized directly, since they may not be valid if the coroutine is resumed in another process. Even if the coroutine is deserialized and resumed within the same process, there’s no guarantee that the handle will be valid at this time.
In the example below, a database connection’s file descriptor (fd) is serialized directly. In another process, file descriptor 23 might point to nothing, or a completely different file or network resource:
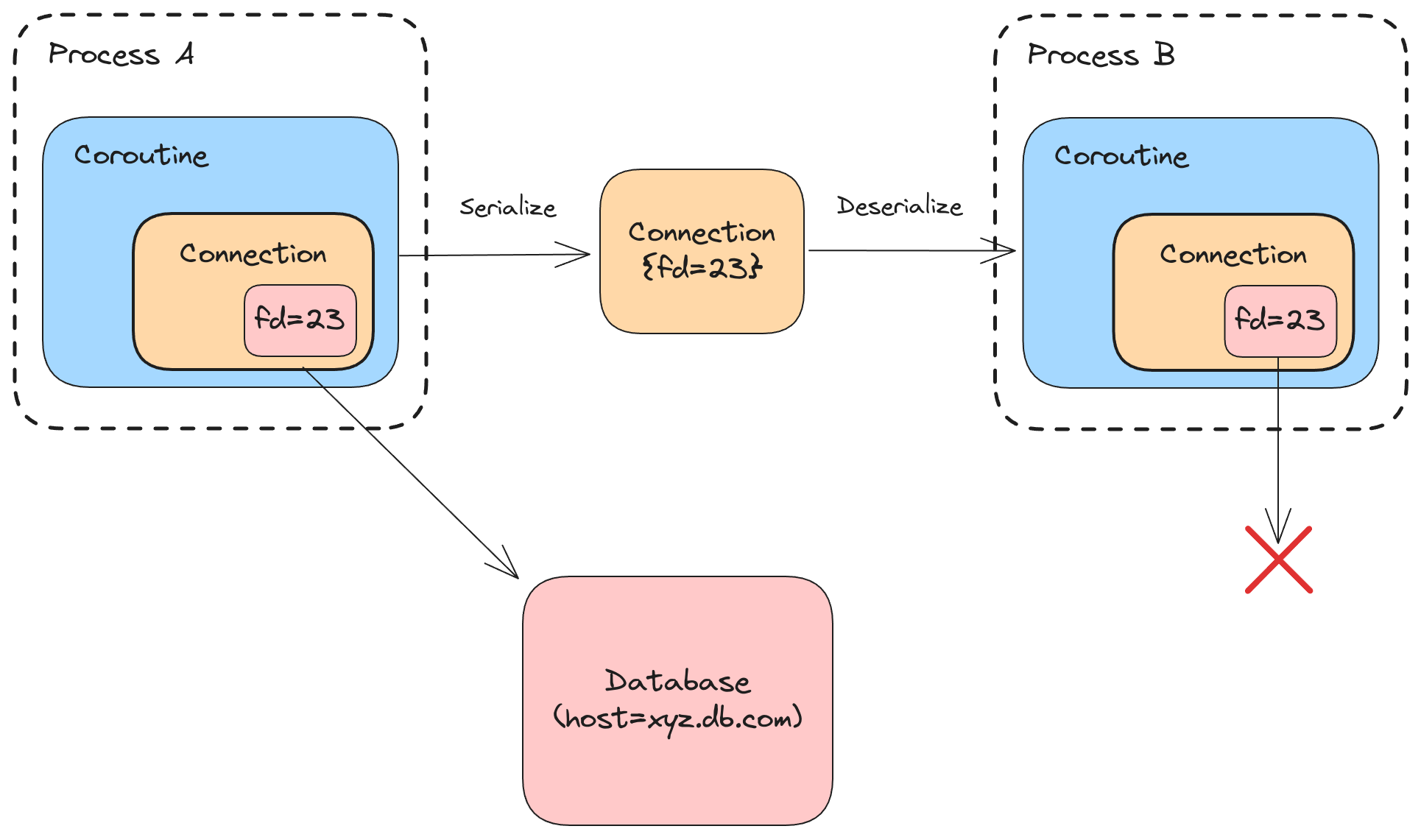
The SDK does not always have enough information to be able to automatically serialize an object like this. The handle can’t be recreated when the information used to create it is no longer available. For example, with open files, the path to the file and the flags that were used to open it may not be stored alongside the file descriptor.
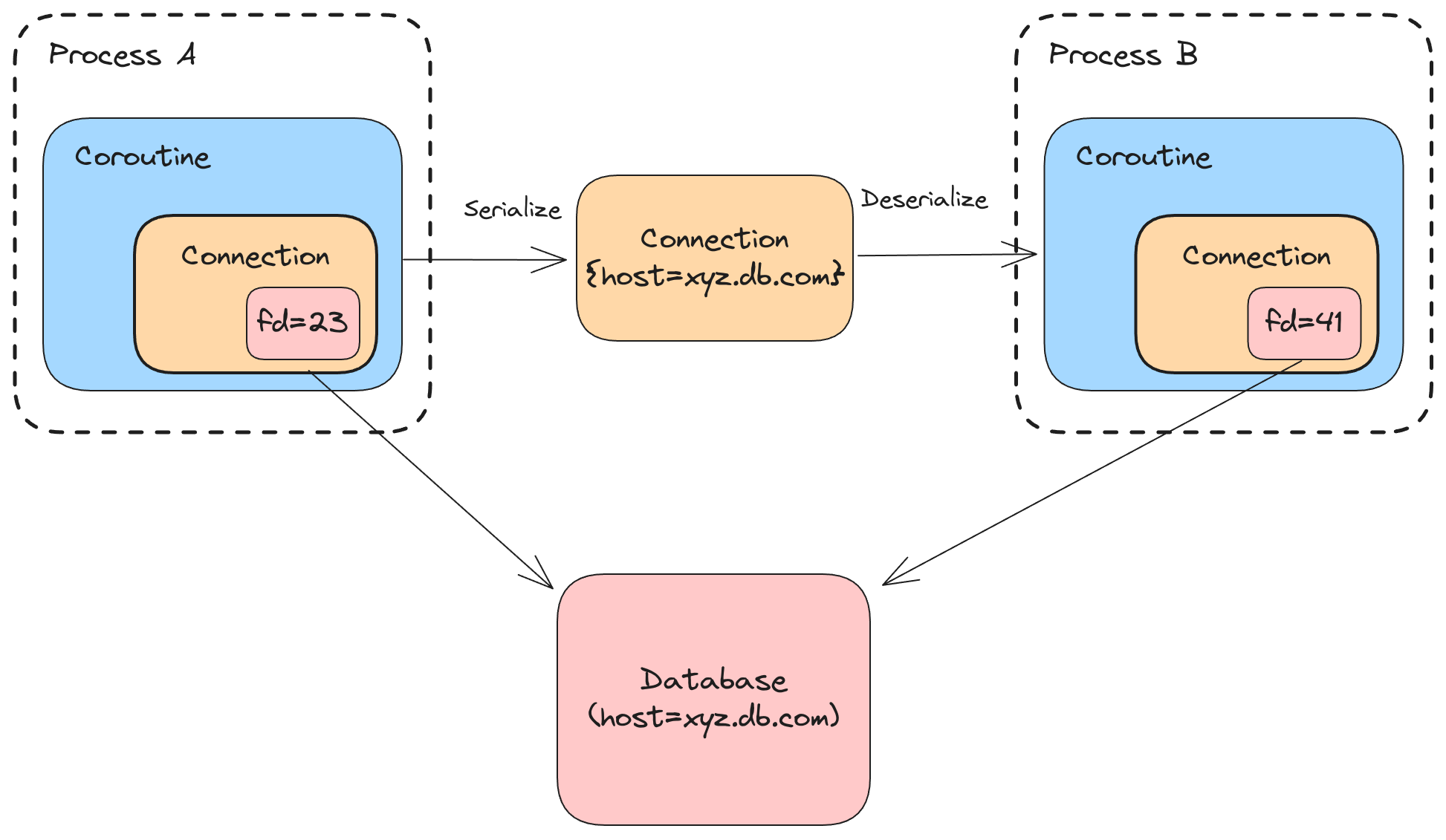
Luckily pickle provides a way to customize the object state that’s serialized. With a little help from the user, the SDK can serialize these objects and then create new, equivalent objects in another process or on another node. For example, a database connection object could define __getstate__ method that returns connection details, such as the database host/port, and then a __setstate__ method that creates a new connection using the serialized details.
Large Objects
The SDK might encounter objects so large it would be infeasible to serialize them and then transfer them across the network each time a coroutine yields control. An example is intermediate machine learning state.
The pickle library natively supports the serialization of references, allowing users to store large objects in cloud storage and then serialize a reference to them. The SDK does not automatically offload large state to secondary storage, but this capability may be added in future. Reach out on Discord if you’d like to know more.
Global Objects
Coroutines can refer to global objects that may be shared by other coroutines.
COUNTER = 0
@dispatch.function
def increment_count():
global COUNTER
COUNTER += 1
The serialization layer has two options when it encounters such an object. It can either serialize the global object verbatim, or it can serialize a reference to the object. Serializing the object directly means that a copy is created in the serialized representation of the coroutine. When a coroutine is resumed, mutations would apply to the copy rather than the original object and the mutations would only be visible locally (per coroutine).
The Dispatch SDK always serializes a reference to globals, with the assumption that they’re used for read-only data and functions that are not suitable for snapshotting. Mutations to global objects are visible to other coroutines running inside the same process, but the mutations are not persistent. For this reason, users should avoid using global mutable objects in their coroutines.
Code & Interpreter Updates
Coroutines allow developers to consolidate code, state and control flow. When serializing Distributed Coroutines, only the state is serialized and stored durably, along with a reference to the code (and its embedded control flow).
The state is intimately tied to the code that generated it, and code inevitably changes over time as features are added and bugs are fixed. The state is also tightly coupled to the CPython interpreter, where implementation details such as the bytecode instruction pointer and stack layout are subject to change over time.
How can we reconcile the fact that state may be invalidated by code changes and Python upgrades? There are two main solutions to the problem: rollbacks, and version pinning.
Rollbacks
The Dispatch SDK includes additional information about the code and interpreter in the serialized representation of each coroutine. The SDK stores the version of the interpreter, and code change markers such as function locations (filename + source line) and code / bytecode hashes. If the code or interpreter changes, the SDK is able to later detect it by comparing versions and change markers.
Although the old state may be compatible with the new interpreter or code, the SDK errs on the side of caution and reports the potential incompatibility to Dispatch with an Incompatible State response. Dispatch initiates a rollback; it throws away the previous state and then invokes the coroutine again with its initial input:
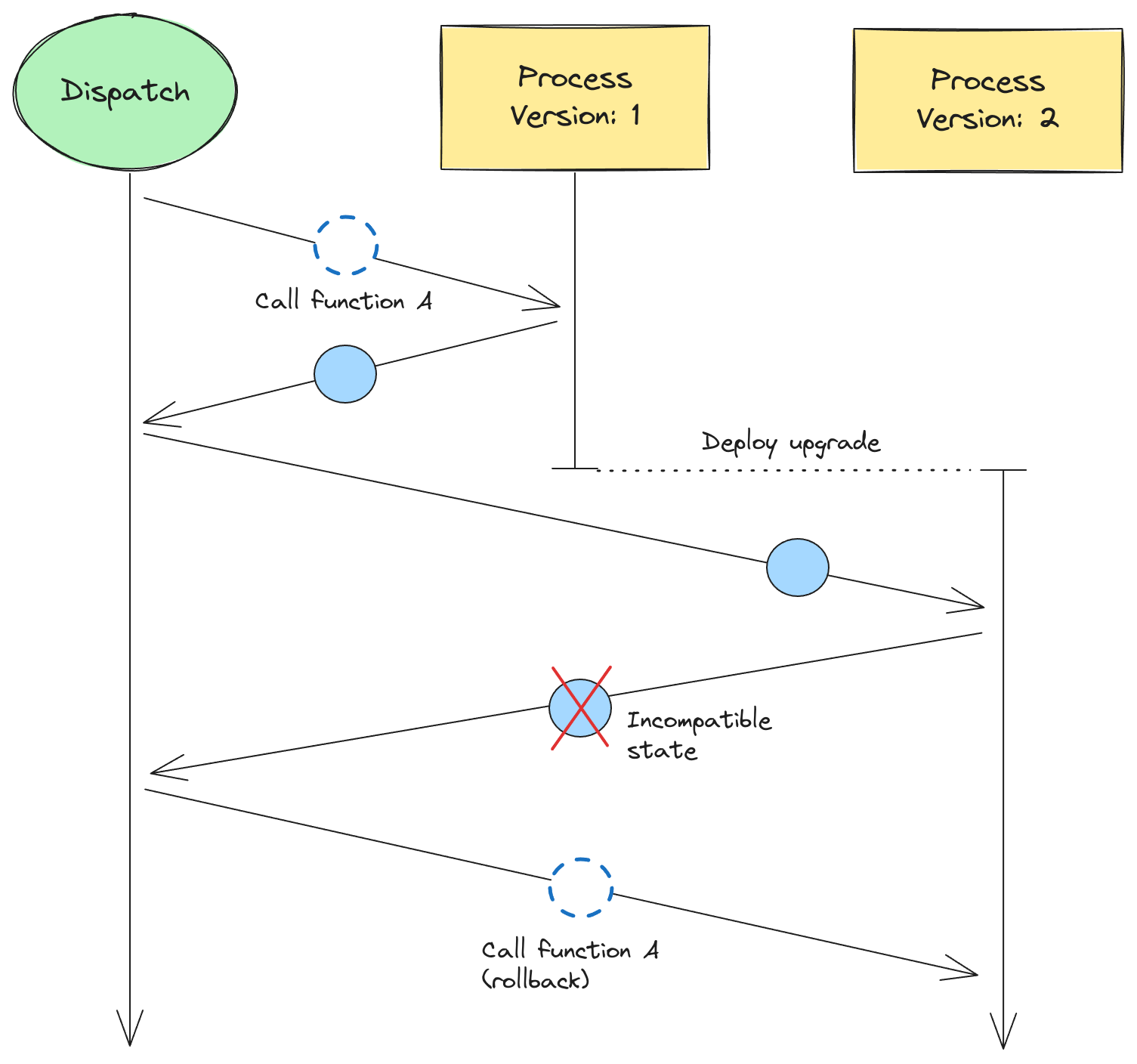
Although there are downsides to this approach, such as having to replay nested operations that were complete, the solution is robust and fits within the system’s at-least once execution guarantees. We are exploring state diffs and partial rollbacks to minimize the amount of state that must be abandoned when using this approach. Reach out on Discord if you’d like to know more.
Version Pinning
Dispatch also supports version pinning. It can call coroutines running inside compute platforms with versioning baked in, such as AWS Lambda. Dispatch sends new work to the latest version of the coroutine. It keeps track of which version each coroutine is running on so that state can always be sent back to the same version. If the Python interpreter is upgraded, and/or the coroutine code changes (as features and bug fixes are released), in-flight work continues to be routed to a previous version:
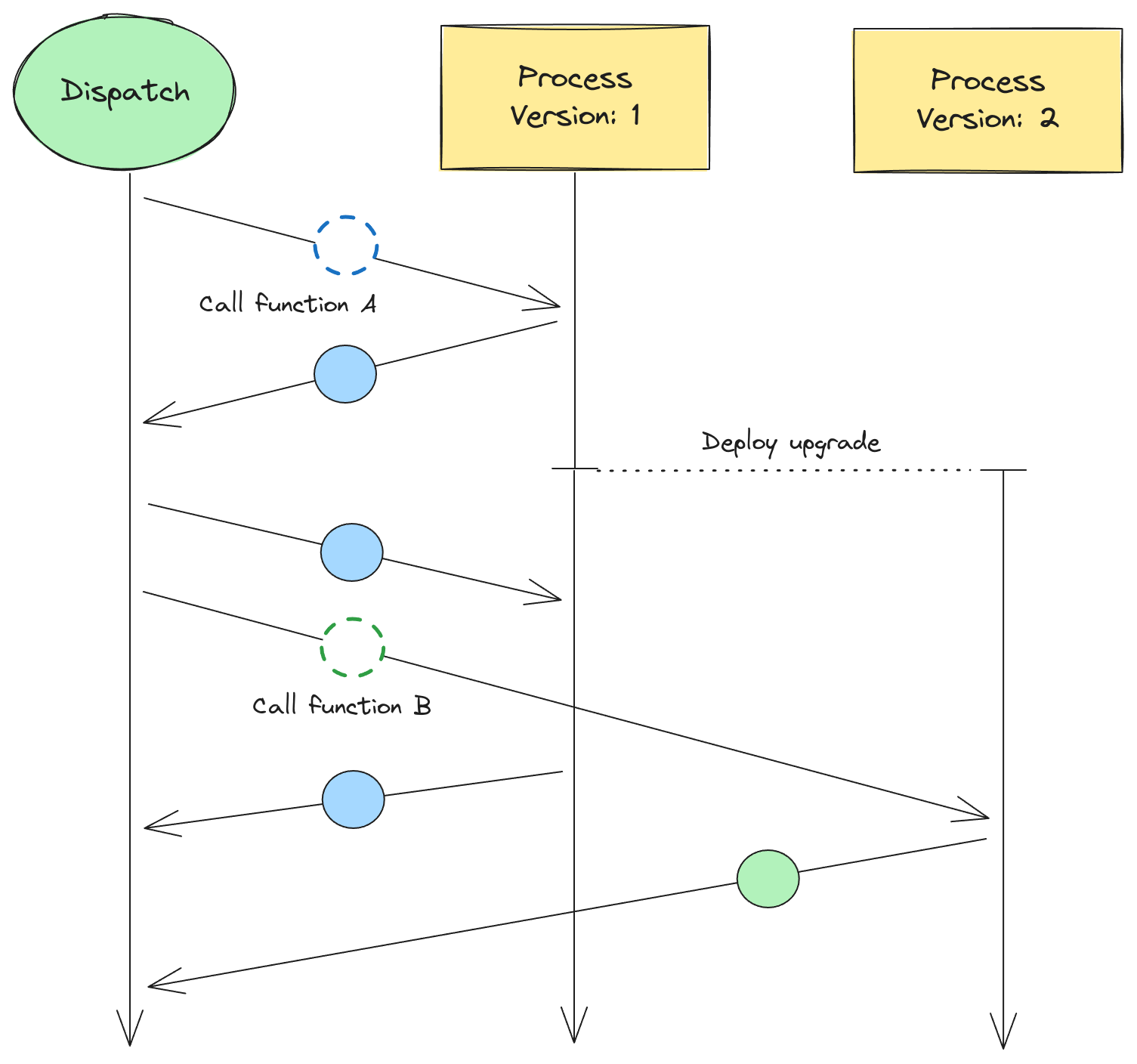
This approach has a different sent of trade-offs, but is ultimately more flexible. We intend to give developers the tools they need to safely and atomically migrate in-flight work across versions if/when they choose. Reach out on Discord if you’d like to know more.
Conclusion
As we’ve seen, a lot goes on under the hood in order to provide a simple programming model for developers.
The Dispatch SDK uses a CPython extension to serialize coroutines (async functions). The location and state of each coroutine is serialized and sent back to Dispatch, allowing it to resume execution at a later stage and potentially in another location. The pickle module from the standard library is used to serialize the graph of objects reachable from each coroutine, and handles hard parts like preserving references and cycles.
The Dispatch SDK bundles a local coroutine scheduler to drive the execution of coroutines. It serializes them once they all reach an await point, before yielding back to Dispatch.
There are many challenges involved in serializing coroutines. The Dispatch SDK handles many of these cases automatically, but some help from the user is still required in other cases.
Sign up to the developer preview for free today at https://console.dispatch.run, and follow us on Twitter and Discord for updates.